

Un communiqué du 10 avril de l’ US Army fait froid dans le dos, mais donne une nouvelle dimension aux relations entre gouvernance et technologie.
Objectif du projet : coordonner l’action de groupes d engins armés autonomes (drones ou robots au sol).
Deux aspects importants : l’importance de la Défense dans le développement technologique, l’ampleur théorique du projet.
Les réflexions
politiques sur les technologies et les réseaux sociaux mettent
surtout en cause les grands acteurs privés (Gafa, BATX). Or le
budget de la Défense des USA est du même ordre que les
chiffres d’affaires du
Gafa. Les uns comme les autres en consacrent une bonne part à la
recherche, et particulièrement
à la recherche en intelligence artificielle. On peut donc en déduire
que ses développements
« exponentiels » sont financés par les Etats que par le
privé.
Les Etats s’expriment assez peu sur le sujet, mais l’US Army n’est pas avare de communiqués comme celui-ci. Et ils comportent de nombreux liens qui permettent d’étoffer la réflexion. On peut commencer par l’Army Research Laboratory. Attention, vous ne serez pas accueillis par de jolis portrais souriants de Jeff Bezos ou de l’attendrissant ménage Gates en pleine action philanthropique. Ici, on fait la guerre. Mais l’Army communique assez largement, avec par exemple cette sélection de vidéos sur Youtube. sans compter un sans complexes Top 19 coolest army science and technology advances. Et bien sûr on ne mettra dans le public ni des scènes trop dures, ni les secrets importants.
C’est pourquoi la richesse conceptuelle du communiqué ci-dessus doit se prendre au sérieux, malgré sa rédaction un peu chaotique. Ici on a les giga-dollars pour réaliser les projets (ce qui certes ne garantit pas la réussite).
Il peut s’agir de très grands ensembles de dispositifs armés autonomes (drones et robots terrestres). Et en prolongeant un peu, en empilant quelques couches hiérarchiques, la totalité des armements pourrait s’intégrer à ce type de disposif. Et pourquoi pas les humains engagés eux-mêmes, ces « soldiers » chers à l’Army.
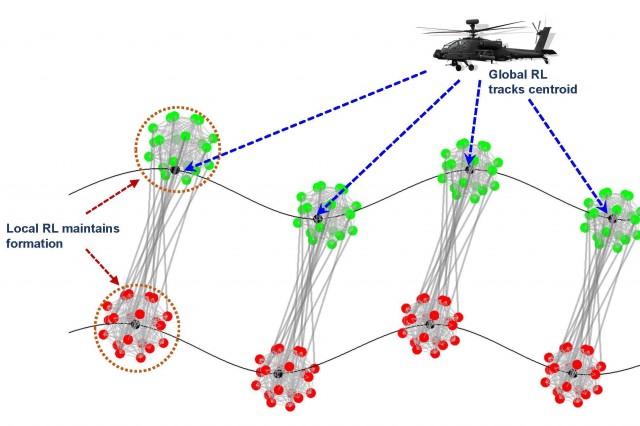 Les
différents niveaux hiérarchiques disposent d’une réelle
autonomie, y compris la faculté d’apprendre. C’est dit au niveau
des essaims (swarms), mais les capacités de calcul d’un simple
drone (de même que le smartphone que vous avez en poche) sont bien
suffisantes pour faire du « learning ».
Les
différents niveaux hiérarchiques disposent d’une réelle
autonomie, y compris la faculté d’apprendre. C’est dit au niveau
des essaims (swarms), mais les capacités de calcul d’un simple
drone (de même que le smartphone que vous avez en poche) sont bien
suffisantes pour faire du « learning ».
La mise en essaim, dit le communiqué « est un mode opératoire où de multiples agents autonomes agissent comme une unité cohérente en coordonnant activement leurs actions. »
Nota : Si vous avez des doutes sur « l’autonomie » de ces armes, Paul Scharre , militaire aussi aguerri que méthodiquement documenté, en a décrit la théorie, l’histoire et les problèmes éthiques. Il conclut que même si tous les pays (occidentaux, ne parlons pas des autres … ) disent ne pas en vouloir… le jour où la patrie sera vraiment en danger, les scrupules tomberont. Voir notre exposé à l'Institut Bull (2019), la présentation du livre par l'Arms Control Association , le livre lui-même : Army of None (Norton, 2018), ou enfin l’une de ses vidéos sur Youtube.
Activement ? Le
communiqué répond selon trois axes :
- l’incertitude,
ou le flou : il s’agit de « coordonner des agents
« incertains » quand on ne dispose pas de modèle précis
de l’agent,
- l’apprentissage par renforcement
(reinforcement learning) ; détail technique :
l’apprentissage se réduirait à la résolution de grandes
équations de matrices (Ricatti),
qui évoquent les réseaux neuronaux sans les nommer
-
l’optimisation, pour attendre des objectifs multiples
(« multi-objective goals »).
En général, dit le communiqué, le reinforcement learning se fait de manière centralisée. Cela exige le relevé par le centre des informations relatives à tout l’essaim. C’est lourd en communications et en traitement. La solution proposée, c’est l’apprentissage hiérarchisé (Hierachical Reinforcement Leaning, HRL). L’apprentissage global est réparti en petits groupes ayant chacun leur objectif (microscopique) et un système global.
On a donc des fonctions d’apprentissage (avec leur reward function) au niveau local et au niveau global. Cela réduit sensiblement les durées d’apprentissage puisque les boucles locales peuvent tourner en parallèle.
Le communiqué n’en dit pas plus. Mais ce qu’il montre donne à penser. En 2012, dans son roman de science fiction Kill Decision (2012), Daniel Suarez nous menait d’abord dans les bunkers de la recherche militaire pour nous conduire vers des destructions catastrophiques dans le Pacifique… avec heureusement une contre-attaque hautemenrt technique qui sauve la planète (nous vous laissons la découvrir). Espérons que l’Army, ete l’humanité en général, sauront se prémunir de telles dérives. Mais entre les tweets de Donald Trump et le totalitarisme de Ji Xinping, tout peut arriver.
Plus sur la Défense Le post suivant Le post précedent L'index général
 Tesla,
un modèle à suivre ?
Tesla,
un modèle à suivre ? 
<>
Vos commentaires
seront appréciés, adressez les à pmberger (at) orange.fr.
A
cette même adresse, dites nous si vous souhaitez recevoir (ou pas)
les nouveaux articles de ce blog.